| These pages are written in ASCII encoding |
|
| These pages are written in ASCII encoding |
|
One of the unique systems we have developped and are using is PARALLEL. Through this system we are able to typeset any critical edition, no matter how complex it is and whatever languages or scripts it contains (including right-to-left or vertical scripts). Let us see how PARALLEL works. In the sample of critical edition below:

which is also available in Acrobat PDF format,
we see five blocks of text: the Greek text, French translation, critical apparatus, references
and footnotes. The critical apparatus entries are identified in the Greek text by their line
number (with the help of a superscript number when the entry is found more than once on the
same line). The references are numbered by lowercase Latin letters and the footnotes by Arabic
numbers. Both numberings restart at every new double page.
| We would like to point out the fact that the page setup and tags chosen here are specific to the given sample of critical edition and can be entirely different for some other case: there is no limitation, neither in the number of different text blocks, nor in their intertextual relations, nor in the number of tags defined. |
In the figure below we show the rôle of each text block and the intertextual relations of different blocks:
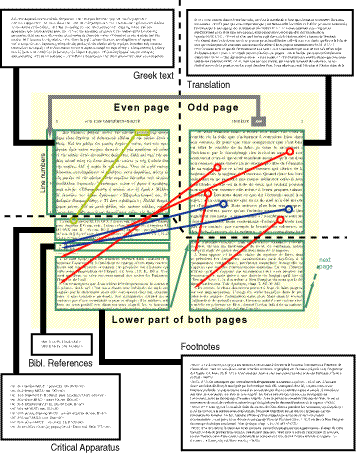
If you wish more detail, see this Acrobat PDF file (don't hesitate to use Acrobat Reader's magnifying lens).
To typeset the double page you see on the figure (with yellow background) our system uses data from five different (pseudo-)SGML files, one for each block of text.

This text contains two kinds of tags: <AC> .. </AC> for teh critical apparatus entries and <Pn> where n is an integer, for parallelism.

Here we have three kinds of tags: <Pn> where n is an integer, for parallelism; these tags have to correspond strictly to the ones of the Greek text file. <NOTE> ... </NOTE> are used for footnotes and <REF> ... </REF> for references.

The same tags <AC> ... </AC> we already encountered in the Greek text file as well as a new tag <MULT> which will be replaced by the eventual superscript number showing the order of our specific entry whenever there are several similar entries on the same line.
![]()
The tag <REF> ... </REF> we already saw in the translation file.

The tag <NOTE> ... </NOTE> we use also in the translation file.
For those who prefer WYSIWYG (What you see is what you get) systems or do not want to type tags (or at least as few as possible) we also provide the possibility of using regular word processors (like MS Word) for preparing the critical edition data. In this case we use the word processor's inherent footnotes for the critical apparatus, references and footnotes. Instead of preparing five files, the user needs to prepare only two. Some conventions have to be followed, for example the fact of underlining critical apparatus entries.
Here you can see such a sample, where the word processor used is Microsoft Word. Don't be shocked by the Greek font: to show that the data editor can use any Greek font on his/her computer, we have taken in purpose one of the most ugly and irrationally encoded fonts of the public domain. This is only an hypothetical example: other conventions can be applied, as long as they are unambiguous and efficient.